Grant has created and led high performance operations teams in some of the largest and fastest growing companies in the UK over the last 20 years. He has been at the forefront of the DevOps movement for the last 10 years. He’s driven real collaboration between Operations and Development teams in AOL, Electronic Arts, British Gas, the Department for Work and Pensions and Just Eat by implementing Infrastructure as code and driving application integration from continuous build systems. Grant has delivered game platforms running in the cloud enjoyed by millions of players per day, websites serving a billion page views per month and Europe’s largest Internet Of Things platform. In addition to writing Next Gen DevOps he has also published his own open source DevOps Transformation Framework available on Github. Grant is frequently sought out for his cloud, DevOps and SRE expertise and can be reached at grant@nextgendevops.com.
View all posts by Grant Smith →
A few months ago Tomek Paczkowski and I were trying to create some well defined bounded contexts out of a set of existing services. This was a classic situation of a start up that had grown and changed as they needed to and the engineers were struggling to extend their services because they didn’t know who was dependent on them and sometimes who they were dependent on in order for their service to keep doing what it was doing. In many cases engineers in different teams had no way of knowing what other team’s services were doing at all. There were a few cases where variable meant something different to Variable and this all needed to be uncovered if progress was going to be made.
It was decided that the best way to document services was to treat them as bounded contexts and discover what inbound data they were dependent on and what outbound data they produced and the rules that turned one into the other.
The organisation had done some Domain Driven Design work and was familiar with the terminology, which meant engineers were familiar with the context. The difficult thing was creating a process so Tomek and I didn’t have to visit every team and interrogate each of them and then to have to go back around when we found inconsistencies.
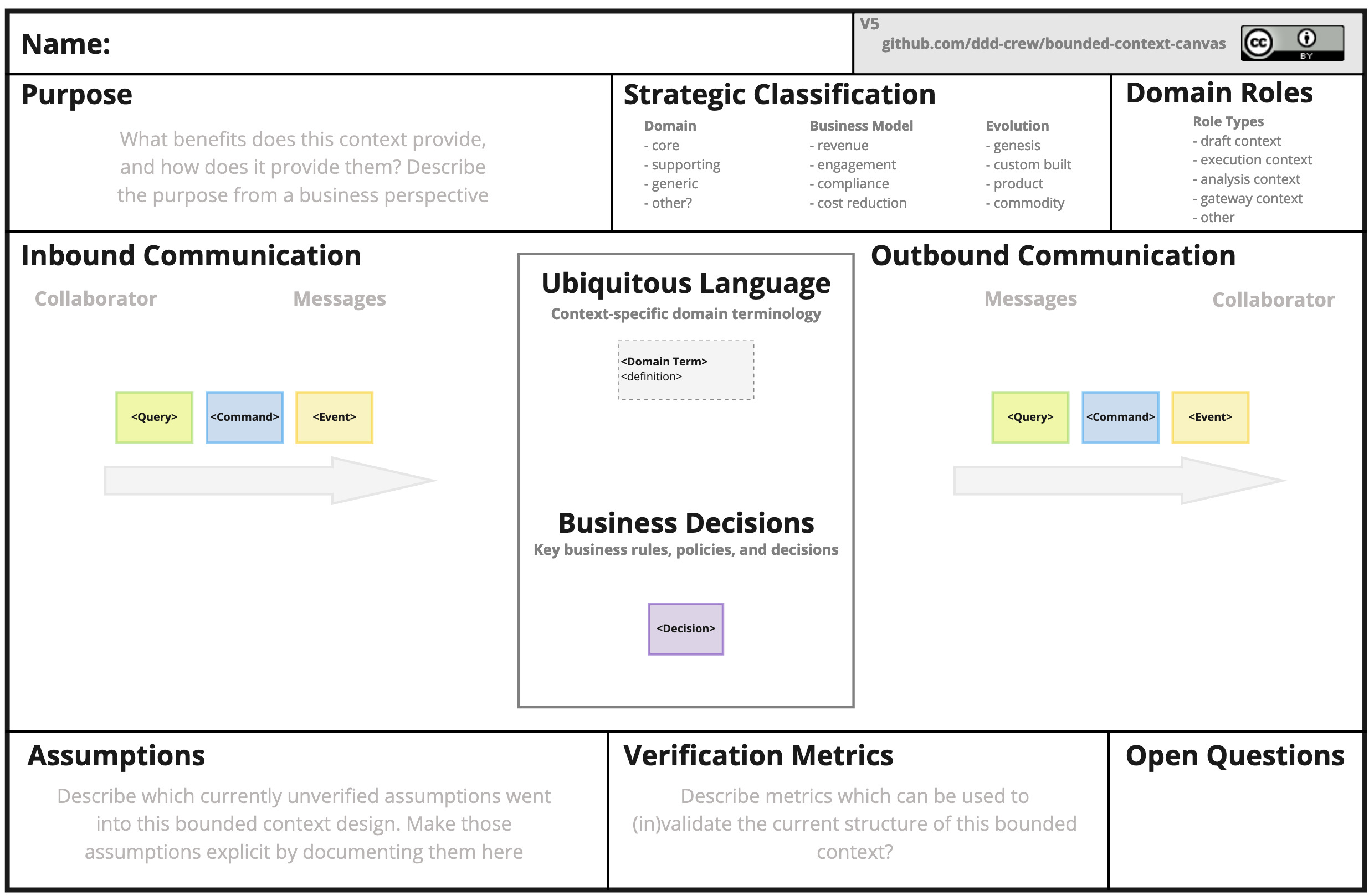
The organisation used Notion for document management so Tomek and I created a bounded context canvas for a service, on a call with the engineers who ran the service to try and extract the details. We used the ddd-crew’s Bounded Context Canvas for inspiration.
We used Cunningham’s Law* to get the engineers to actively contribute and eventually take over the exercise and populate the information for themselves. This not only worked beautifully but it took us less than an hour to get a good first draft of each bounded context.
* “The best way to get the right answer on the Internet is not to ask a question; it’s to post the wrong answer.” – Howard G Cunningham
The DDD Crews Bounded Context Canvas template looks like this:
When we started the meeting Tomek shared his screen and he started building the template on the fly. In this first meeting we had some preconceptions about the service we were discussing so Tomek and I would make some suggestions about how we thought it worked. The team quickly got frustrated with us getting it wrong and they just started modifying the document with what was actually taking place. Less than an hour later we had fully documented the service well enough that we could now use the information to talk to one of the teams with a service upstream.
The next conversation went even faster than the first because we now had some documented facts, in a useful template and the second team could see what was expected of them. It worked really well! I’ve since used the approach in another, larger organisation with similar problems and it worked just as well again.
So if you want the template and a full README with descriptions about how to get the best from it you can check it out here:
I really thought we had fixed this. I was thinking of retiring Next Gen DevOps because it was out of date having been published 11 years ago. Sadly it isn’t. If your development teams need to beg for favours from your ‘platform team’ in order to get things done then you’ve recreated the nightmare of the Ops team. If the term ‘beg’ offends you then feel free to substitude the term ‘agree priorities’.
In this post I am going to give some helpful advice about how to enable your development teams to get to production without any blockers AND minimise their toil AND ensure your infrastructure is built safely and securely and in compliance with all your companies standards.
The key to enabling the development teams is to free them from things they don’t need to care about in order to ensure the quality, performance, availability and security of their applications. Equally the key to having a platform team that can enable the development teams while also ensuring infrastructure is built securely and compliant with all company standards it where to draw the line. On Amazon this looks something like this:
Creating the VPC
Creating all the subnets
Creating the Internet Gateway
Creating the NAT Gateway
Mapping the public and the private subnets
Creating all security groups
Creating Policies
Creating CloudWatch Log group
Creating secrets using secrets manager
Creating Parameter Store
Creating Load Balancer
Creating Target Groups
Creating Listener
Creating ECR Repositories
Preparing the docker images
Creating IAM Roles and Policies
Creating ECS cluster
Creating ECS task definitions
Creating ECS services
The items above the line are global cloud configuration, cost management controls and should be owned by the platform team. The items below the line are application specific configuration and should be owned by each application team.
This split should be agreed and regularly reviewed by the engineering community as a whole. If items below the line are seen to be toil, by the application teams then they need some training to teach them how to reduce that toil for themselves.
As with security we trust but we verify compliance with company standards. These should be tested by running scripts and using AWS Anomaly detection.
One of the key points I make in Next Gen DevOps is how the concept of operations teams went wrong because they had different priorities from the teams building applications and generating revenue. That point is just as valid for Platform teams today as it was for operations teams ten years ago.
If you’re an Engineering Leader and you are considering creating a platform team pay close attention to what their priorties and motivations will be. If they are ostensibly motivated by safety and cost control and your application teams are motivated by revenue and experimentation then you’re going to have problems. You have one team pulling and another pushing. If you want some help thinking through this and aligning the priorities then get in touch or buy the book.
I’m writing this in the days immediately preceding my 50th birthday. It’s common for people to engage in some self-reflection when they hit the decade birthdays. Usually mine revolve around my achievements. Did I achieve enough over the last 10 years? Did I change what I wanted to change? Am I proud of what I’ve done? Have I helped people? What comes next?
I’m writing this post, in part for me, as all blog posts are, but in part for the people younger than me. I want to share something with you that I think would have helped me as I approached 30 and 40.
Systems over goals
A key to my philosophy is systems over goals. Throughout my life I’ve found goals stressful and demotivating. I used to think that was a weakness in my character or a lack of discipline and I spent years beating myself up about that until I decided that they just don’t work for me. So instead if I need to achieve a goal I work backwards from that goal and ask myself what routines, systems, tools, teams, processes, etc. do I need to have in place so that if I work everyday that goal gets achieved as a natural consequence of my routines. That unlocked an enormous joy in achievement for me. So if you’re someone who hates goals consider that approach.
Job titles are less important than achievements
Job titles are less important than what you do. When I was 30 I wanted to be a CTO. I thought of my career as a ladder I needed to climb. I thought that the level of influence I wanted to have required me to achieve the highest position. At the time, in 2004, I saw that CTOs were often from a Telco background, or if they had done software engineering work it was usually in a pre-internet context and they weren’t focusing sufficiently on quality, system design and live service operations. This is why every launch was bad and organisations were optimising too late after they had already lost customers and damaged their reputations. Some things happened, I learned some things about myself and about what’s expected of a CTO and I realised that it wasn’t the right role for me. After a lot of soul searching and thinking I realised that I could achieve my goal of improving quality and systems in a company and across the industry without the need for a CTO title. The important realisation was that I focused on what I wanted to achieve as opposed to focusing on a job title that freed me to use my creativity to figure out how to have that influence that I wanted.
On reflection…
Having provided a little free advice allow me the indulgence of a little public self-reflection. Stop reading here if you’re allergic to cringe. I am really happy with what I achieved in my 40’s. I helped British Gas with their public launch of Hive, I helped the DWP with their DevOps journey, I helped Just Eat improve their reliability. I sold a few thousand copies of Next Gen DevOps (which is more trouble than it’s worth from a tax perspective but I hope I helped at least some of those people on their DevOps journeys). I switched my focus from DevOps to digital transformation and I helped Zoopla build their new tech stack. For the last 2 years I’ve built a team of permanent consultants here at 101 Ways and am mentoring and coaching my team, helping them grow in their careers faster than I did. It’s been a pretty good decade. Also I am thankful everyday for the NHS. Arthritis and diabetes hit me like a hammer during lockdown and thanks to the amazing NHS consultants, doctors and nurses I am pain free and fitter and healthier than I’ve ever been.
If you’ve just achieved a Head of, Director or VP role then congratulations! You probably earned that role because of your performance in your previous role. The problem now is that you’re being asked to do things you haven’t really done before and probably haven’t even seen done very often.
An individual contributor is surrounded by people doing a similar job that they can look to for guidance. A new manager has seen management up close for at least a couple of years. In addition to that managers will usually receive some form of guidance from human resources to help them manage their team. In contrast a new leader may not have seen leadership before. In most departments there is usually only one head of, director or VP and Individual contributors and managers never see them work together. There is very little training available for leaders. There are coaches but they aren’t always made available to new leaders.
Being a successful leader requires a different set of skills and approaches than being a successful individual contributor or manager. Being the best engineer, delivery manager or product manager in your department is not going to make you a successful leader. If you find yourself telling your people to give you what you need to let you write that document, or code or create the plan then you have fallen into the trap of the Super-doer.
In your 1:1’s, your boss may be telling you that they don’t want you to do the job they want you to lead your department. You probably think that the best way to do that is to protect your team from all the pressure you’re experiencing. You’re probably working late and sometimes on weekends in order to get the job done. If this is you then I’m afraid you are a super-doer, not a leader.
The best description of the role of a leader I ever heard was: To create an environment where the teams can be successful. That is a great test to determine if you are leading or doing. If you are explaining what good looks like, encouraging your people to try and achieve it and you are praising good behaviours, you are creating an environment where people can be successful. If you are frustrated that your people aren’t doing as good a job as you would and you’re taking the work off them and doing it yourself then you’re doing it yourself, you’re not leading.
I know the work is very important. I know the future success of the organisation depends on it being just right. That just means you need to do as good a job as you can of explaining what is needed and ensuring your people have time to do the work, that they have the support they need and that you can work it through with them and guide and, if absolutely necessary re-write the executive summary ;).
When you lead teams well there is a joyous virtuous circle. Not only is the work done well, but you get to help your people grow and experience their excitement as they learn and contribute. All the praise and the glory you heap on your team comes back to you and you get to do that for every team in your department. It’s an incredible feeling. When you are failing to lead your teams well you will feel the burden of all of theIR work, as though it’s all on you so you try and do it and there aren’t enough hours in the day. Your team will seem sullen and frustrated and they may even seem to be working against you.
If you feel like you are failing as a leader then congratulations you’re in good company. Every new leader with an ounce of self-awareness feels that way. The question is will you try and learn how to do it better?
There’s a phenomena that happens to a lot of successful technical people. We meet the bigger fish and we get better for it. I want to tell the tale of how I met my bigger fish because he’s just died and it might help me process his death.
Jon Ward and I weren’t mates. He was my boss 24 years ago and we probably met up half a dozen times in the last 10 years or so but Jon will always be with me because he was my bigger fish.
In 1998, I was 23, I worked at Compuserve and I was given an amazing opportunity. I didn’t do a Computer Science degree so I had to take the long route to get into technology. I started in Customer Services and found my way to running Compuserve’s QA lab. The Sys Admin team left one day and I got the opportunity to take over managing compuserve.co.uk and the office firewall. It went great! I hired a couple of great contractors, we fixed a bunch of annoying problems. I was on top of the world, I was doing what I wanted to be doing and it only took me 3 years of working to achieve my goals. I was living my best life!
The time came to build the permanent team. I interviewed Jon and when he accepted I was informed that Jon would be the manager of the team and that I would report to him. I was not amused. I thought I’d earned the right to run this team. My brother from another mother: Dave Williams, the sensible one of our dynamic duo, told me to stop throwing a tantrum and take the opportunity to learn from this experience. I did and I’ve never regretted it.
Jon taught me a lot about tech, things I’d never heard of, things that Microsoft downplayed at the time. Jon taught me how to use the \net use commands to automate command line tasks in Windows NT. Jon taught me how to manipulate the registry to automate Windows NT installations. In 1999 I was automating deployment and software build tasks 10 years before anyone coined the term DevOps. Jon also taught me the natural talents I had that were rare, I’ve built on that knowledge over the last 20 years and had a great time doing it. Jon also taught me the power of simplicity. When I was getting carried away with my own cleverness or when I was intimidated by how difficult something seemed to be he would say: “It’s just web servers and databases” in this smug way he had that I found equal parts annoying, amusing and reassuring.
If you’re an engineer in your late 20’s and you’re successful and you think you are a living gift to the technology world then look out for your bigger fish, I hope you find one as good as Jon Ward. RIP.
A question I’m often asked is: “How do I measure the health and productivity of a product delivery team”. The question can cause a lot of stress as the people being considered often assume the person asking is trying to measure them by some objective measure and to compare one team to another this doesn’t lead to any useful conclusions but there are indicators that a team could use some help and these are the ones I use.
Before getting into the indicators I start by assessing some initial principles. If any of these aren’t true the chances of the team being healthy and productive are low:
Do the team have an appropriate level of responsibility, accountability and authority over what they are building?
Do the team have a good understanding of who they are providing solutions for and how well those solutions are working for those people?
Are the team working with tools, processes, systems and technologies that they want to be working on OR are they happy that they are part of an initiative that resolves whatever problems they might have with the tools, processes, systems and technologies they are working with.
If all those things are true I can start looking at some more objective measurements to get a sense of whether the team is doing good work. If they aren’t true we need to fix those things before we measure anything.
The measures I care most about are:
Time to onboard new developers
If it takes more than one or two days for a new team member to review part of a solution and contribute something useful to it then that is a sign that the systems or the solution is too complicated or poorly documented which is a sign of poor health.
DORA Metrics
Deployment Frequency
Lead time for changes
Mean time to recovery
Change failure rate
The DORA metrics are useful because if you attempt to game the metrics you still end up with a good result. If you game Deployment Frequency and release even ridiculously tiny changes like config variable changes you still force your pipeline to run quickly or your lead time for changes increases and you have to have good testing or your change failure rate increases.
Estimation metrics are useful for a team to have a view about itself but they aren’t of much use to anyone else. The characteristics of their burndown charts are a useful indicator that a team might need support.
If the burndown is flat and then drops off a cliff, there’s a clue that the team is not managing their work well or are not well informed about their requirements.
Large downward vertical drops indicate that the team is tackling work that is too large and might have been passing a story from week to week for too long. Large upward vertical inclines suggest the team has been tackling too large a piece of work and have suddenly discovered they need to break something down in several smaller stories. Neither of these things are necessarily bad but they are indicators that a leader might want to get closer to the team to see if they need help.
Conclusion
Those are the most important measures, once I’m happy with those I then focus on the items below.
You’ll notice that there is no attempt to measure productivity objectively. That’s because it’s unecessary and impossible in software engineering. If you object to the idea that measuring productivity is unecassary then you should read about Theory X and Theory Y. Software engineers are internally motivated they don’t need someone telling them they aren’t productive enough, they know when they’re being productive and they will tell you when they aren’t! If productivity is inadequate it will be because something isn’t right and the answer will be exposed by one of the measures detailed on this page. The reason objective productivity is impossible to measure is because no two software problems are ever exactly the same. Even if the problems seem identical there will be some external factor that will make it different. The difference might be as trivial as a minor version upgrade of a dependency or it could be something as major as a combination of browser upgrades, cloud system upgrades and a different team with different experience. Either way comparing two teams trying to solve the same problem is fruitless.
If all the principals mentioned above are true and you have the measures in place for the metrics I mentioned and something still isn’t right then continue to read the additional measures below that can help pinpoint precisely where the problem is:
Good understanding of their role and place in the strategy
Skip level 1:1s are a useful tool to determine if a team has a good understanding of the wider business strategy and how that has informed their product roadmap and the features they are building. If a team member can’t explain what they’re doing in the context of the business strategy there is a real chance that the team isn’t in a position to make good decisions about their solution.
How long PRs wait for review, or how many PRs are waiting for review.
Charting these metrics by team can be useful to identify when a team is overburdened or when a team is working on something they are struggling with. A platform team with a lot of PRs or a long-lead time for reviewing PRs could indicate they are overworked or it might indicate training needs in the teams consuming the platform.
Focus
If a team of six is tackling six stories simultaneously there is a chance that it isn’t a team it’s six individuals. There’s some nuance to this, if they break their stories down well and split an epic between them and act as reviewers for each other then it could be a healthy sign but more often than not it’s more healthy for a team to tackle one or two objectives at once and to work together on them.
Systems/Application scorecard
If a team’s systems and applications are meeting all the organisation’s security, compliance and engineering standards then the team is likely to be doing good work.
This solution was so successful the teams were actually motivated to race each other to be first to get all A’s or who could get the Spectre badge we offered for the first team to patch the Spectre and Meltdown bugs.
This scorecard should include the four golden signals.
These notes are lifted straight from the Google article linked above.
Latency
The time it takes to service a request. It’s important to distinguish between the latency of successful requests and the latency of failed requests. For example, an HTTP 500 error triggered due to loss of connection to a database or other critical backend might be served very quickly; however, as an HTTP 500 error indicates a failed request, factoring 500s into your overall latency might result in misleading calculations. On the other hand, a slow error is even worse than a fast error! Therefore, it’s important to track error latency, as opposed to just filtering out errors.
Traffic
A measure of how much demand is being placed on your system, measured in a high-level system-specific metric. For a web service, this measurement is usually HTTP requests per second, perhaps broken out by the nature of the requests (e.g., static versus dynamic content). For an audio streaming system, this measurement might focus on network I/O rate or concurrent sessions. For a key-value storage system, this measurement might be transactions and retrievals per second.
Errors
The rate of requests that fail, either explicitly (e.g., HTTP 500s), implicitly (for example, an HTTP 200 success response, but coupled with the wrong content), or by policy (for example, “If you committed to one-second response times, any request over one second is an error”). Where protocol response codes are insufficient to express all failure conditions, secondary (internal) protocols may be necessary to track partial failure modes. Monitoring these cases can be drastically different: catching HTTP 500s at your load balancer can do a decent job of catching all completely failed requests, while only end-to-end system tests can detect that you’re serving the wrong content.
Saturation
How “full” your service is. A measure of your system fraction, emphasizing the resources that are most constrained (e.g., in a memory-constrained system, show memory; in an I/O-constrained system, show I/O). Note that many systems degrade in performance before they achieve 100% utilization, so having a utilization target is essential.
…
Finally, saturation is also concerned with predictions of impending saturation, such as “It looks like your database will fill its hard drive in 4 hours.”
While Core Web Vitals are a web application performance metric they also provide a view into how well a team is able to observe, orient, decide and act (OODA) the speed of a team’s OODA loop is another insight into how healthy a team is. Each aspect of the OODA loop can provide insight into where a team might need help:
Observe: Does a team have access to the right signals? Do they even know how their app performs?
Orient: Is the team able to review those signals in context? Does the team know if their application performance is acceptable?
Decide: Can the team use the information they have in context to make decisions? Can the team make the difficult decisions necessary to balance their application requirements against Google’s expectations expressed in the Core Web Vitals?
Act: Having decided what to do can the team actually implement the change in a reasonable time frame?
The OODA loop is an essential component of the Lead time for changes in the DORA metrics.
Measurable improvements to business Outcomes
The ultimate purpose of a product delivery team is to achieve some desired business outcomes such as customer acquisition, or conversion. This isn’t always easy to measure but some attempt must be made to describe what success means for that team. If success is building a feature with no link to the reason why that feature is being built the team will inevitably get stuck on requirements and may be accused of gold-plating their solution.
Experimentation rate
The time taken for a team to design an experiment, agree the conditions for the experiment and time or results required for conclusion of the experiment and then generating insight is a useful metric to describe the health of a team, their understanding of their users and quality of their solution and the tools they have to manage it.
Retros
Team retrospectives are a good indicator of team health. I always tell my teams that I won’t attend their retros so they can feel free to criticise or comment on anything they want to and then I ask them to provide me with a summary of whatever they feel comfortable sharing. I can then use this to try and determine what issues might be impacting the team.
Team health checks
Team health checks have become quite popular recently and there are a few different solutions that are summarised quite nicely in this Medium article written by Philip Rogers
NPS is a useful tool but needs to be used sparingly, once a quarter is about as often as you can ask for an NPS score before people get frustrated with the process.
The biggest problem facing the DevOps, Operations and SRE professions are also the root causes of the biggest mental health issues in the profession. I touch on this subject in the book but I wanted to write something a little more personal here.
Most DevOps, Operations and SRE teams work on their own in their technology departments. Increasingly developers, testers, business analysts, scrum masters and product managers are aligned inside product teams. If they aren’t actually in a team together they are tightly bound by shared goals and success criteria. This has not been without trauma all of these groups have struggled with their identities and their relationships with each other but have generally had well aligned goals. It’s becoming more common for all these groups to report to a single Chief Product and Technology Officer.
DevOps, Operations and SRE teams might also report into this person or they might report into a separate CIO but regardless of that they are almost never given any attention as long as the core platform is working. When those systems aren’t working they are placed under tremendous pressure, as the whole business stops and all focus is on them.
If people are treated this way they inevitably become defensive. If this treatment continues defensive will become belligerence in some people.
I was at AOL in the early part of my career. Our Director of Technology clearly wanted nothing to do with operations. His entire focus was on the development teams. On my better days I told myself that it was because we were capable and functional in operations and they needed more help than us. On my worst days I’d tell myself that he didn’t understand operations and didn’t want anything to do with us.
I had a great boss (Dave Williams, now CIO of Just Eat, because he complained that I didn’t namecheck him in the book :P), and he always kept me focused on our capabilities and our achievements and stopped me getting too wrapped up in departmental politics. This strategy worked well. Operations grew in capability and size but every interaction I had with the director of the department went wrong. During crises I didn’t look like I cared enough. My people were belligerent and I was inexperienced. I didn’t know it at the time but we were pushing the envelope of technology and it was never commented on. Had it not been for Dave giving me air-cover and support I would probably have performed some career-limiting- manoeuvre. I certainly came close a couple of times.
It was Dave’s support that gave me the freedom to think about my profession and how things should work that eventually led to my realisation about product-focused DevOps or SRE as it’s more commonly known. Focusing on the needs of the developers gives clear success criteria when they don’t come from the leadership. Skip forward a decade-and-a-bit and I put all these things into practice at Just Eat. This created an environment for the people in SRE where they knew exactly how to be successful. Further it encouraged the people who developed software for the customers to discuss what shared success looks like with us. Some of the best work we did at Just Eat arose from having conversations with developers about what they were struggling with and designing and building solutions to help them out. Few things are more fun that making your friends lives better.
If you are unloved in your technology department and you aren’t getting the support you need from your boss then seek it from your peer group. Meet with your colleagues in development, testing, business analysis and product management work with them to make their lives better, build friendships with them and get your support from shared success.
I’m excited to announce a new edition of Next Gen DevOps. Newly subtitled A Managers guide to DevOps and SRE. This third edition, has been comprehensively restructured and rewritten as a definitive guide for managers.
I wrote the first edition of the book in 2012, at that time, as hard as it is to believe now, many senior technology leaders remained unconvinced about the DevOps paradigm.
I felt this very keenly when I was working on my DevOps Transformation Framework. For any readers that don’t already know it wasn’t my initial intention to write a book at all. I wanted to create a framework for DevOps transformations. As I worked on the framework I realised that many of the assertions I was basing the framework on were unproven to many in the Industry. I ended up creating so much exposition to explain it all that it made more sense to collect it into a book.
I’ve had loads of great feedback in the 7 years that the book has been available. Over that time the main criticism I’ve received is that the book wasn’t instructional enough.
The book wasn’t originally intended to be instructional, that’s what the framework was for. The idea was that if executives could see where the old silos of development, testing and operations were failing and could see a clearly presented alternative thoroughly proven from first principles and supported by anecdotes they could work with their leadership team on their own transformation programme that suited their organisation. That’s where the Next Gen DevOps Transformation Framework would come in to help them to structure that transformation.
That isn’t what happened. Executives were convinced of the rightness of DevOps by a vast weight of evidence from multiple sources. Evidence like Puppet’s State of DevOps reports, various Gartner analyses, pitches from new specialist consultancies like Contino and the DevOps Group (who were eating the older consultancies lunches in the DevOps arena) and recruiters like Linuxrecruit and Esynergy and a huge wealth of success stories of which my small book was merely a drop in the ocean. These executives were then challenging their teams to create transformation programmes. Managers were then looking to my book, and others like The Phoenix Project, to help them figure out what good looked like.
Unfortunately my book wasn’t hitting that spot, until now. This new edition is aimed squarely at those managers looking to migrate development teams to DevOps working practices or operations teams to SRE.
Since I published the second edition I’ve provided strategic leadership to the Department for Work and Pension’s cloud and DevOps migration programme and helped Just Eat improve their resilience and performance and transitioned their operations team to SRE. This new book adds experience from both of those initiatives.
I’ve learned a new technique for creating departmental strategy from business goals which I’ve included in chapter six. I moved the popular history chapter to an appendix as it’s inclusion confused some readers. The point I was trying to make (and if I have to explain it I’ve clearly failed) was that the separate development and operations silos were the anomaly not DevOps. By moving that to an appendix I’ve been able to create a smoother flow from the problem through to the solution and on to a new chapter about building DevOps teams, which includes a lot of information about hiring engineers. I’ve changed the management theories chapter into a chapter specifically about managing DevOps and SRE teams. Following on from that chapter five details how DevOps teams work with other teams. Each subsequent chapter has been re-focused away from transforming whole departments down to transforming individual teams. I haven’t removed any content so if you are looking for guidance about changing an entire technology department that is all still there. In addition to that there is now a wealth of guidance to help managers transform their teams and supporting their peers as they transform their teams.
If you bought either of the first two editions I’ll send you a free PDF of the new edition, if you email me at grant@nextgendevops.com with a picture of you holding a copy of the book in paperback or showing on your e-reader and give me permission to use those pictures in a future blog post.
I first heard of Amazon’s Cloud Centre of Excellence (CCOE) concept back in 2016, to say I was cynical would be an understatement. There was a fad, back in the late nineties – early 2000’s to call your team a centre of excellence. As with all such things many of the teams who adopted the moniker were anything but.
Earlier this year, I was at Just Eat, and our Amazon account manager mentioned the CCOE again. We had a good relationship and he fully understood the product-focussed SRE transformation that I was bringing to Just Eat. Again I scoffed at the idea. Just Eat have been in AWS for a while, they have all the fundamentals locked down. Just Eat’s cost management and infrastructure efficiency is the best I’ve ever seen. The security model is sound and well implemented. The deployment tooling is mature and capable and unlike many who migrate to AWS Just Eat are still innovating, they didn’t just stick with the services that were in place when they first migrated. What did we need a CCOE for?
I suspect Amazon have this problem all the time. We’re all busy, we’re trying to satisfy multiple different stakeholders who all have conflicting requirements. We’re trying to grow our team’s capabilities and improve the current solutions while also exploring new capabilities. It can be hard to look up from all that to see the opportunities that are being offered to you.
This is particularly embarrassing for me to admit. I maintain that SRE teams need technical directors because someone needs to be free from the details so they can focus on the longer term strategic goals. Unfortunately I had a bit of detail I couldn’t delegate at the time and I missed the opportunity that Amazon presented me with.
If you haven’t read my book, Next Gen DevOps, you might not know what I’m talking about when I talk about product-focussed SRE.
I maintain that the software we use: Ansible, Chef, Cloudformation, Docker, Dynamo, Kinesis, Kubernetes, Puppet, Packer and all the others are not what’s important. What matters to the organisations we work in are the outcomes we deliver from the products we build with these tools. What matters to developers are that they have reliable, consistently configured environments. What matters to finance teams are that we are demonstrably using infrastructure efficiently. What matters to our engineers is that they can see how what they’ve built contributes to the business’ success and their personal growth.
These are the things that provide value to our customers, the developers, finance people, and security teams. Not the software, languages, configuration and infrastructure that go into making them. These products need vision, roadmaps, budgets, and objectives and key results.
Product-focussed SRE describes an SRE function that recognises that their products exist to server their customers first and foremost and be grounded in real customer needs before we even consider the technology.
Amazon describe the Cloud Centre of Excellence as:
I already knew Amazon shared my view about product-focus. It was obvious, EC2 exists because Amazon needed a fast way to provision servers for Amazon.com. Jeff Bezos’ insistence that all teams built their services with APIs made it possible for Amazon to sell EC2 as a service for the rest of us and the cloud was born. However the Cloud Centre of Excellence takes this idea a step forward, they are now recommending that their customers adopt a product-focus too.
This article was co-written with Anthony Fairweather Product Manager for SRE at Just Eat when we were discussing it he gave me this lovely little snippet (that I suspect he wrote for a presentation):
“In the platform team @ Just Eat we’ve embedded a continuous cycle of user engagement (with our engineers) and a prioritisation methodology that ensures we’re always focussing on the outcomes that deliver the most value. Our definition of value is fluid, depending on the business context we are operating in and the risk profile we’re carrying. Think of this like a pendulum that swings between reliability and development velocity.” Anthony Fairweather
At the beginning of the year I contributed to an article Appdynamics put together called ‘The State of DevOps at the Start of 2017‘. I joined a motley collection of contributors with a broad range of backgrounds who all answered an interesting array of questions. If you’re unlucky enough to work in one of those organisations that’s still debating the relative merits of DevOps then I think this little article gives a nice concise summary of the current state of the industry.
Standardisation
Since I started shamelessly self-promoting my DevOps prowess I’ve been asked to contribute to a few of these things. There’s usually one question that really piques my interest and gets me thinking. In this piece it was the question:
“Do you think DevOps will become more standardized?”
Software Fragmentation
As this piece was sponsored by AppDynamics I initially started thinking about software and services. In the early days of the DevOps movement there was a real danger that it would get written off as merely Continuous Integration. That focus spawned a plethora of software and plug-ins. Then when the #Monitoringsucks movement gained momentum it heralded a wealth of new approaches to monitoring tools and solutions, Outlyer (formerly known as Dataloop.IO) started in earnest, Datadog and the Application Performance Management tools started to really gain in popularity. Splunk and ELK become the standards for log-processing. All throughout this period various Cloud solutions launched. Redhat integrated various open-source solutions into an entire private cloud solution together which it put forward as a competitor to VMWare.
I was just putting an answer together about how at the start of major new trends in IT there’s always a profusion of software solutions around as organisations try to capitalise on all the press attention and hype when it occurred to me that the approach organisations have taken to adopt DevOps practices have become highly standardised.
Regardless of the exact mix of software and cloud solutions we always try to automate the building, testing and deployment (and more testing) of software onto automatically provisioned and configured infrastructure (with yet more testing). What has varied over the years is the precise mix of open and closed source software and the amount of in-house software and configuration required.
1st Generation
In the beginning before Patrick DuBois first coined the term DevOps Google, Facebook and Amazon all had to create automated build, configuration, deployment and test solutions to support their meteoric growth. Facebook had to create their own database software and deployment solutions. Amazon ended up building the first cloud solution to support the growth of their ecommerce site. Google had to create programming languages, frameworks and container ecosystems.
2nd Generation
The second generation of DevOps organisations including Netflix and Etsy were the first generation to be able to piece together pre-existing solutions built around CI tools like Jenkins and Teamcity to build their DevOps approaches. That’s not to say they didn’t have to build a lot of software, they did but Netflix were able to build on top of Amazon’s Cloud and Etsy relied on Jenkins and Elasticsearch among other tools. In technology circles Netflix are as famous for their codebase as they are for their video-on-demand service. While Etsy are perhaps a little less famous for their code their contributions are arguably much more influential. Where would we be without Statsd? Etsy’s Deployinator was responsible for driving a lot of the conversation about continuous integration in the early days of DevOps.
3rd Generation
I think we’re getting towards the end of the 3rd generation of DevOps. The current approach to abstracts us even further away from the hardware. It’s built on the concepts of containerisation, microservices and serverless functions. We’re trying to build immutable services, very rapidly deployed and automatically orchestrated. The goal is to support the most rapid test and deployment cycle possible, to minimise the need for separate functional and integration test cycles, to make the most efficient use of resources and allow us to scale very rapidly to meet burst demand. The software we’re forced to build at this point tends to be integration software to make one solution work with another and expose the results for analysis. Rather than building our solutions around CI tools we’re building them around orchestration mechanisms. We still need the CI tools but their capabilities aren’t the limiting factor anymore.
4th Generation
I think the next generation of DevOps will bring data management and presentation under control. Too often we choose the wrong data stores for the types of data we’re storing and the access patterns. There’s still a tendency to confuse production data stores with business intelligence use-cases. We’re still putting too much business logic in databases forcing us to run large data structure updates and migrations. We also need to lose the idea that storage is expensive and that everything must be immediately consistent, we also need to manage data like we do software in smaller independant files.
Standards
From the perspective of the daily lives of engineers and their workflows DevOps appears highly standardised. We haven’t standardised around a small number of software solutions that define how we work as previous generations of engineers did we have standardised our workflow. We’ve been able to do that thanks to the open source movement which has given us so many flexible solutions and made it easier for us to contribute to those solutions.