I have a bit of an unusual entry for you this week. I’m doing a little work with a small online ad service business on a new project. The challenge has been to choose technology solutions that allow the agency to deploy it’s expertise without needing a large technology team of it’s own and that are completely transparent to our partners and clients. By that I mean I want to provide solutions that provide impartial reporting and if possible API access to the service so no reconciliation is needed and we can minimise middle-man problems. With the wealth of software-as-a-service solutions available at the moment the challenge has actually been to decide which solutions to reject rather than trying to decide what to use.
The latest challenge is availability and performance monitoring. In my last company, Connected Homes, we had a hybrid monitoring solution using Pingdom and Dataloop.IO. Pingdom was a great solution for providing impartial uptime statistics on the external facing sites so that when we achieved 100% in a given month I wasn’t accused of fiddling the figures :).
In the project I’m working on right now I want to go a step further. I want to be able to provide our partners (the sites we publish ads into) and the ad networks and clients (the people who request we run an ad for them) full visibility into our availability and performance.
I’m trying to establish partnership relationships with everyone involved. After all if we all do our job well then everyone benefits, including the visitors to the sites. If any one of us under performs we all suffer.
There seem to be hundreds of monitoring options out there but from talking to friends and doing a little research of my own I’ve settled on five to choose from, they are:
They all offer slightly different services and so before I start comparing them I should specify what I’m particularly interested in:
- I’m just looking for a simple HTTPS Get. All our content is hosted on Rackspace’s CDN, Cloudfiles or on a 3rd party ad-server such as Google’s Doubleclick so I have no server monitoring to worry about. I only really need to make 1 GET request per partner because all the variables beyond that are stored in the ad-server itself. I assume that if I get one response back from the ad-server I’ll get a response to any query. If this turns out to be false later I’ll need to update my test but so far it looks true.
- Our partners often have global solutions and so I need to monitor availability and performance from different locations around the world. I don’t need to know exact performance in each major city so as long as I can do a test from most continents I’ll consider that sufficient.
- I would like (but it’s not completely essential) some level of application performance monitoring. Online ads are relatively simple get requests (that lead to a few more gets) so I’m not looking for real APM but if a particular aspect of the ad-serving process is slow I want the data to know what the problem is.
- I need the monitoring solution to provide an API so our partners can pull monitoring data directly into their own monitoring solutions should they choose to.
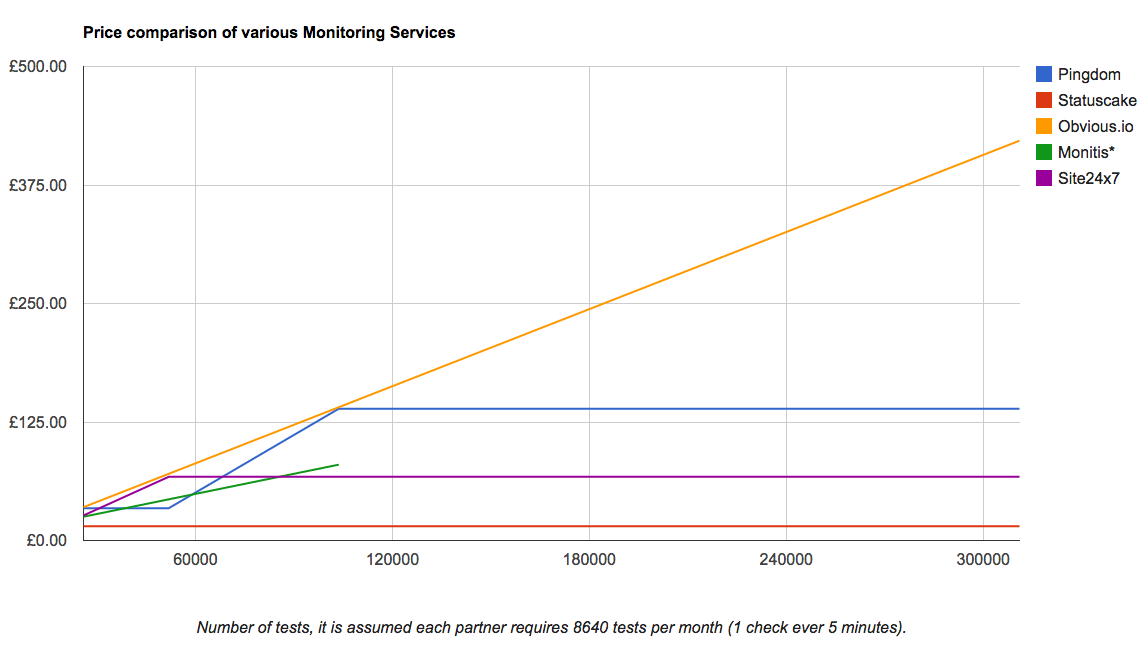
The business is just starting and they only have a few partners (although several are very large) signed on at the moment so I’ll start by assessing the costs of 3 partners (which equates to 3 ads given each ad is just a different query to the same ad-server). We’ll then scale to 6, 12 and then 36 partners to see how prices scale. I have decided that monitoring every 5 minutes will be sufficient which means each partner will require 8640 tests per month (assuming a 30 day month).
Each service charges differently and offers slightly different features at different price points so we’ll have to make certain assumptions as we go along.
Now that I know the features I need let’s see if any of my requirements cause problems for any of the monitoring services.
Pingdom
Pingdom list four price ranges on their site, they’re all priced monthly with a discount for annual subscribers. I’ll start by assuming the business wants to pay monthly. Pingdom then allows users paying more to have more checks, more RUM sites (Real-User stats), more page views, more SMS’s and the like.
Pingdom offers to test site performance from multiple regions but only actually offers Europe, the US and Australia, that’s not a bad spread but I know some of our partners have significant interests in the far east so it’s far from ideal. However Pingdom isn’t out of the running yet because it offers Real-User-Monitoring. By adding a little Javascript into my pages I can collect performance data from the actual users of the sites. In some ways that’s better than synthetic test data but it does mean I now need to pay enough that each of my partners can get sufficient RUM sites. This pushes me almost immediately into the higher price bands.
Pingdom offer website performance monitoring.
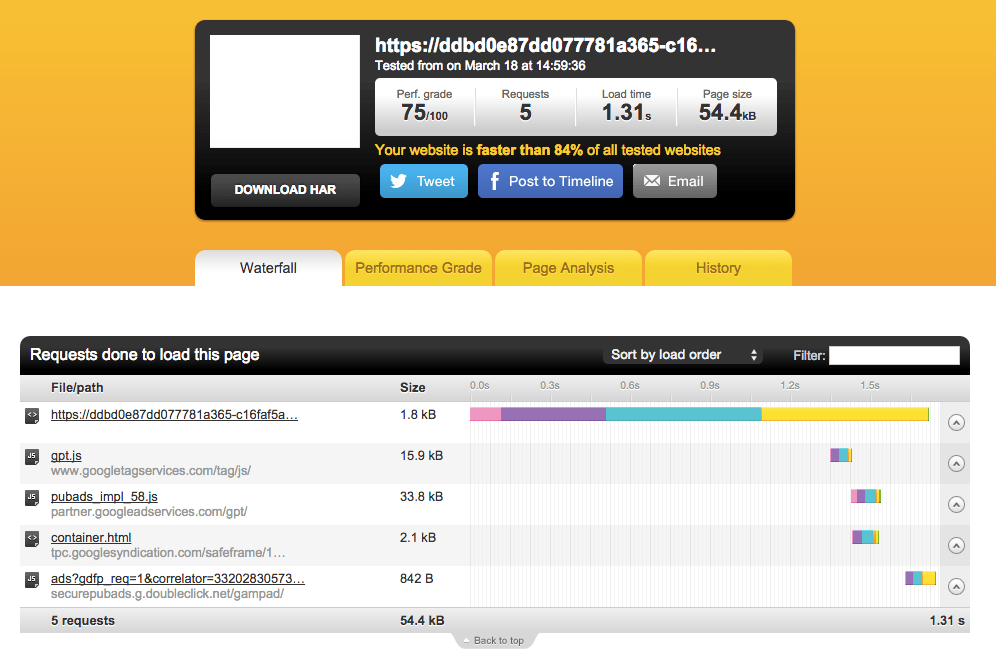
In the case of simple web applications like mine this provides a nice little performance breakdown similar to those available from within a browser. The advantage here is that the test is performed from one of Pingdom’s test sites.
While Pingdom offer access to their API at all price levels access to that API is by using the main account’s Email address and password. Clearly I can’t have our partners sharing accounts with us so I now need to pay extra for multi-user access to the API. This now means for any size monitoring task I need pay at least £139 per month for the professional access. I would have needed this when we get 12 partners anyway but it’s a shame that I’ll need to pay that price even when we just have our first 3 or 6 partners.
Statuscake
Like Pingdom Statuscake list four price options on their site. With Statuscake the higher price rangers allow tests to be run more often from every minute to every 30 seconds to constant. The higher price brackets allow access to more test locations, more SMS credits and access to additional features which we’ll get to later.
Statuscake offer a wider range of test locations than Pingdom they provide a nifty little map showing the locations available.
At the time of writing they have 118 monitoring locations according to their API. Although it should be noted that only 8 of these are available at the lowest price point, it isn’t clear whether you get to choose which 8.
While Statuscake make a point of specifying that their web tests are performed with a webkit they don’t offer a real-user reporting feature like the one Pingdom provide. In my particular case I’m less concerned with real-user reporting than I am testing from locations that are important to my partners. I only mention it here because if I choose Pingdom real-user monitoring is the only way I’ll get adequate test coverage whereas I don’t have that restriction with Statuscake.
API access is with a unique API key. Clearly this isn’t something I want to give out. Statuscake offer a 3rd party access mechanism using api service keys and web hooks to allow users to integrate with other services like Pagerduty. This mechanism should allow me to provide partners to query test test status.
All these features appear to be available at the lowest price point.
Obvious.io
Obvious.io take a different approach to pricing than the other monitoring services in this group. They simple charge $0.002 per check. On the one hand I love this approach, on the other it’s feels very restrictive at scale. Then again I don’t think these monitoring services are really aimed at large scale enterprises.
Obvious.io claim test locations across the USA, Europe and Asia but provide no details. Assuming their infrastructure is hosted in AWS or a similar cloud infrastructure this might be sufficient for my purposes. It’d be nice to have a little more information about where they can monitor from though.
Obvious.io brings a new feature to the table that might actually prove very useful for online advertising. Obvious.io offers visual website monitoring. Obvious.io can compare regions of a website to a snapshot it takes at the time the monitoring is configured and alert if it looks different. This would only be only useful for the static parts of the page but online ads tend to be updated every two weeks so I could set up a monitor for each campaign to ensure the right ads are being served at all times. This could be a great solution for direct campaigns. It’s probably not such a great idea for programmatic campaigns.
Unfortunately Obvious.io makes no mention of an API so it doesn’t look like I can give third parties access to monitoring data. This rules Obvious.io out for me but it might still have a secondary use if I want to set up the visual monitoring for direct ad campaigns.
Monitis
Monitis, the premium version of Monitor.us has a very nifty pricing calculator so rather than providing various products at fixed prices you can configure exactly what you want and discover what the cost will be. This was very useful for me because it allowed me to tailor the service exactly as I wanted it. The downside is that they don’t allow any very many monitors and sub-accounts before deciding that you’re not allowed to use the calculator anymore and you need to contact them.
Monitis offer a huge number of monitoring locations and as well as specifying them on their site they even provide you a handy guide of the IP address each monitoring location uses: http://www.monitis.com/support/tools/our-ips/. Monitis also offers real-user monitoring, they have standard plugins for WordPress, Joomla or Drupal but for everyone else it just requires pulling in another Javascript from Monitis.
Monitis also offer excellent online help for setting monitors up, in this guide when I was looking into how to set up an HTTPS check I also discovered that this monitor can also check for a text string in the source code for the site. This is nice because you can even check that your whole page is downloaded.
The Monitis service includes a REST API which supports using an API key and secret key or authentication but goes a step further and allows the use of public keys this should mean I can allow 3rd parties to query my monitors and get test results for themselves. The API document also appears excellent at first glance.
Site24x7
Sie24x7 returns to the classic 4 tier pricing model and again each tier increases the number of monitors allowed, the polling frequency and provides access to more features.
Site24x7 don’t seem to specify exactly where their test locations are on the site. They do comment in their FAQ that most pricing options offer 8 locations. Site24x7 offer a nice little set of free tools and playing with the ping and website availability tools tells me that five of their locations are probably USA, Canada, Singapore, India, Australia this alone is quite a nice spread. It’d be nice if they also had somewhere in Europe and Japan. These tools also tell me that my readers in India are not getting the performance they should be.
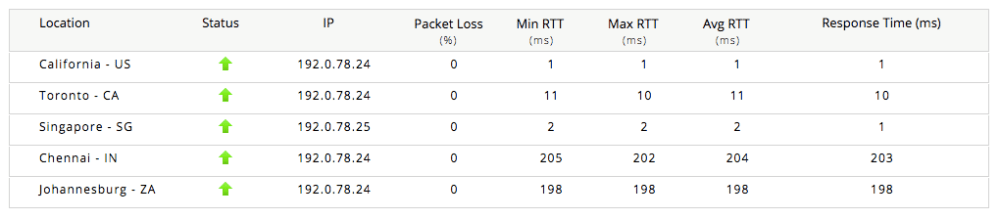
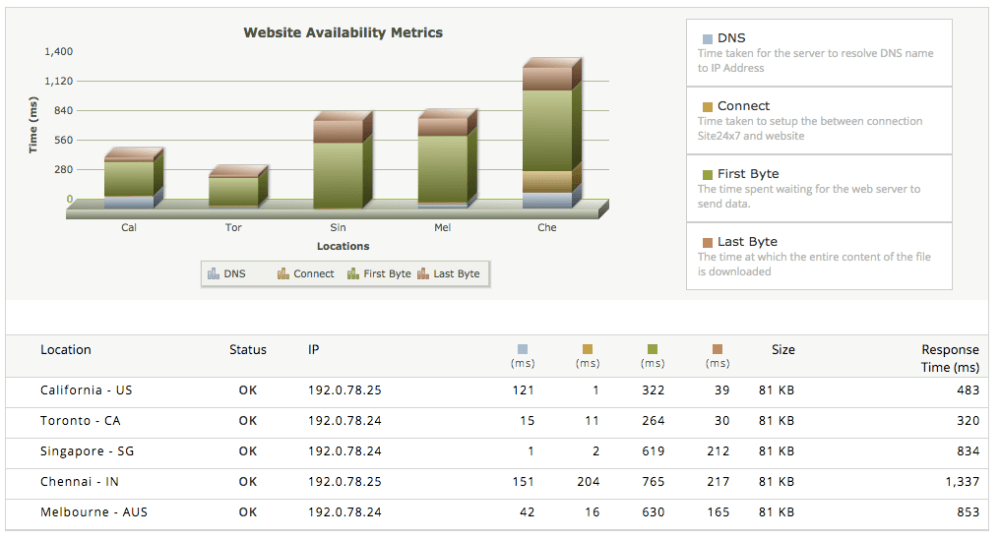
On the subject of free tools Site24x7 offer so many that I felt they had to be applauded for their work. Along with a ping and website availability check they offer webpage performance analysis, DNS checks, IP resolution, geo-ip checks, port availability, tracerouting, SSL certificate monitoring, heart bleed vulnerability checks, Poodle vulnerability checks, and IPv4 and IPv6 subnet calculators and that’s just the System Administrator tools! They also offer validation tools, content tools and developer tools!
Site24x7 also offer a REST API they even go so far as to comment that one of the use cases they’ve designed their API for is to allow service providers to provide custom monitoring services to their clients. They do this by allowing the generation of multiple API keys. I hope the different API keys can be given different permissions but I couldn’t find a note to that effect in the documentation but given it was designed for this purpose it would seem stupid not to have this feature.
Price
Each of the monitoring services is priced differently and aimed at slightly different use cases. All we can do is consider our specific case and try and find the closest fit. The last piece of this particular puzzle is price. Not being an expert in each of these services I’ve done my best to determine the options I’d need to select in order to get the service level I’d like. For the sake of brevity I won’t detail every choice and option here’s how it breaks down.


As expected Obvious.io gets very expensive at scale. The price for Pingdom is artificially high because I included real-user-monitoring on every test. This was necessary because their test locations are so limited.
Summary
Pingdom
I don’t have the option for using real-user monitoring at this stage of the project so that rules Pingdom out straight away. That’s a shame because I’ve had a really good experience with Pingdom in the past. The reality is that the web is global and not offering any monitoring options on the Far East or India just won’t cut it anymore.
Statuscake
Offer a really good fit. The pricing might be artificially low because their £14.99 price point only offers 25 SMS’s and while I don’t expect many failures I can see that being consumed really quickly if we make a mistake implementing a new project. Upgrading to £49.99 per month would then provide unlimited SMS and more test locations and being Statuscake’s price more in-line with some of the other providers in this assessment. However the £14.99 price point is very tempting for the early days of the project.
Obvious.io
The ever-scaling price and lack of an API rule Obvious.io out for the primary use case but I think the visual website monitoring could be useful. It may be a suitable add-on for use later on. However for now it doesn’t make the cut.
Monitis
Monitis were the surprise inclusion for me. I’d never heard of them before, they turned up in a Google search and I included them because they looked to be doing the right sort of thing. It’s a shame their online price calculator only allows relatively small scale because it’s difficult to tell whether prices would keep rising. As it is for the purpose of this assessment I can’t take them any further because I just don’t know what might happen to the price at higher-scale. If I struggle with implementing whoever the eventual winner is I may return to Monitis and give them a call simply because of the quality of their documentation.
Site24x7
I haven’t used Site24x7 before but they were recommended by a friend, ex-colleague and brummie I trust. I wish they provided more information about their test locations and the permissions management options for their service keys. It all sounds good and the pricing is good but I do have some questions unanswered.
Choice
There may well prove to be problems during implementation, either my starting assumptions will be incorrect or API access won’t work as I hope it will so I’m going to choose an order of preference rather than one clear winner at this stage.
- Statuscake
- Site24x7
- Monitis
I hope this has been useful for you. If anyone has any information about any of these providers that they think would benefit readers or help me in my selection and implementation then please leave a comment or send me an email grant@nextgendevops.com